本来是打算在今年暑假,辞职完之后,来美国之前,写一篇年记的。彼时刚好距离上一次碎碎念记录过去一年,可惜拖延症以及即将赴美时躁动的心情使得我一直没有动笔。今天是圣诞节,距离新的一年还有五天,每天写一点,我想,再怎么拖延也应该在元旦来临之前记录一下这可能对我的人生来讲非常重要的一年半吧。
当然,很多时候,现在觉得重要的东西,未来会觉得无足轻重。不过所谓成长,或者我更喜欢说成是,生活,就在这一重一轻之间吧。
本来是打算在今年暑假,辞职完之后,来美国之前,写一篇年记的。彼时刚好距离上一次碎碎念记录过去一年,可惜拖延症以及即将赴美时躁动的心情使得我一直没有动笔。今天是圣诞节,距离新的一年还有五天,每天写一点,我想,再怎么拖延也应该在元旦来临之前记录一下这可能对我的人生来讲非常重要的一年半吧。
当然,很多时候,现在觉得重要的东西,未来会觉得无足轻重。不过所谓成长,或者我更喜欢说成是,生活,就在这一重一轻之间吧。
记录一下【线段树】的个人模版。
记录一些好用的线段树的模版。线段树不仅能处理区域和还能处理区域积、区域最大值、区域最小值等一切可以用分治法计算的问题。
相较于树状数组更据灵活性,因为树状数组只能处理区域和(通过前缀和解决)。而同时线段树的所要求的时间复杂度也更大,树状数组是O(n),线段树是最小O(2n),一般为了方便找到子节点用O(4n)。
作为Google大数据时代三架马车之一的Bigtable: A Distributed Storage System for Structured Data,其中的理念,模型和设计思想依然影响着许多当下大型数据库的设计。不过,作为一个经受过无数业务考验的大数据产品,其背后细致入微的工程设计是无法完全在论文、博客中得以体现的。笔者作为一个刚入门大数据领域不久的新人,在工作当中时常会接触到HBase(Bigtable的开源实现),便想读一读这篇经典的论文,记录下阅读和查找资料过程当中的思考,尚不曾仔细地研究过一些开源项目。希望未来能在参与一点相关的工作过后能有更深刻的理解。
记录一下【树状数组】的个人模版。
BinaryIndexedTree主要功能是提供动态的O(logn)时间复杂度内计算前缀和。树状数组和线段树是不同的实现方法,树状数组的设计目的是为了更高效地计算前缀和,而线段树的设计目的是更高效的计算区间和,二者在如“和”这种简单计算上可以互相替代,毕竟计算前缀和就能计算区间和,计算区间和就包括计算前缀和。但实际上,线段树面向的不仅是区间和的高效计算,它的分治法可以处理任何具有二段性的计算;而树状数组更多的是利用了加法和二进制的某些特性。
有人也许会问,什么时候需要用到这些高级数据结构。如果只是计算静态的前缀和,当然不需要引入这些;但是如果想要动态地去进行计算,数组中的元素发生更改时能够在O(logn)内计算出新的结果,那么这些高级数据结构便是必要的。
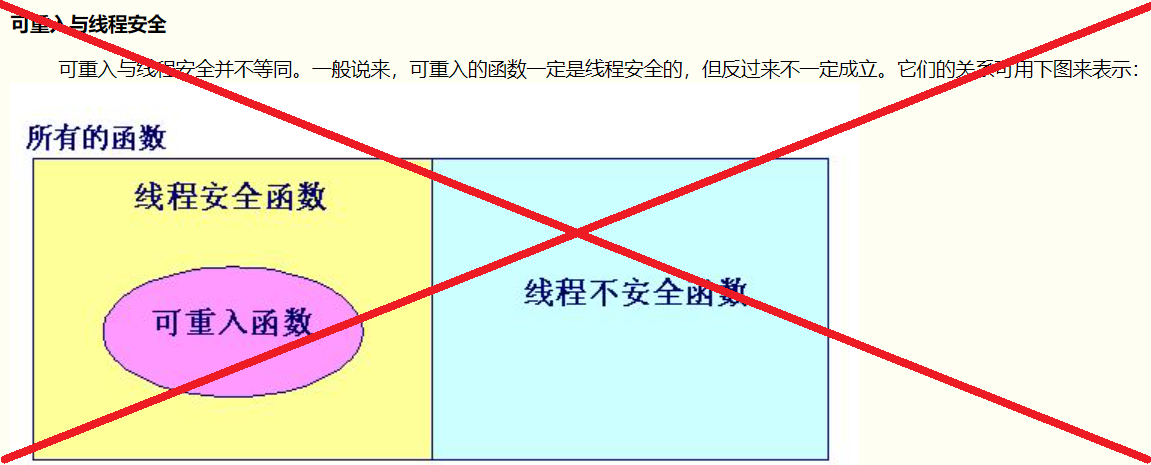
在百度搜索关键词"可重入和线程安全"跳出来的第一篇被抄来抄去的博客堂而皇之地写道“可重入函数一定是线程安全的”,还煞有介事地画了一张图。但实际上,Wikipedia的词条Reentrancy(computing)上非常清楚地说明了二者不存在任何充分必要条件。
为了应对面试官的提问:Kafka如何选举啊😣
背景:大规模延时任务、周期性任务、定时任务的存储和处理
例子:支付订单在30分钟内如果没有完成就应该取消;Kafka中在acks=all的情况下处理生产者请求,在一定时间内如果没能达成所有的同步副本写入消息就返回异常;Dubbo中调用失败,延时重试等
需求:设计一个合理的数据结构存储这些等待中的请求,使得整个系统能够高效地插入、检查、清理和执行这些任务
敲crud代码的时候,想要建一个包含特定key的map,但是这个key所对应的value可能是不一样的类型。因此最原始的解决方案就是给所有类型的value都写一个相应的函数来生成这个map。突发奇想,是否可以写一个函数,通过泛型之类的方法,在函数的参数中指明要生成的类型呢。
之前觉得人总是在回过头看的时候才会发现自己走了这么长的一段不得了的路,但是实际上回头看的时候只会觉得当时多么困难的事情并没有什么值得骄傲的。在今年春招的时候总是想着结束后要写一个总结来记录这多么不容易的过程,但当现在真正拿到offer后似乎又没啥动力去写了。我觉得我总是在不过不管怎样,大学生涯的最后一个学期里干的最主要的事情,也许还是有值得纪念和分享的价值吧。