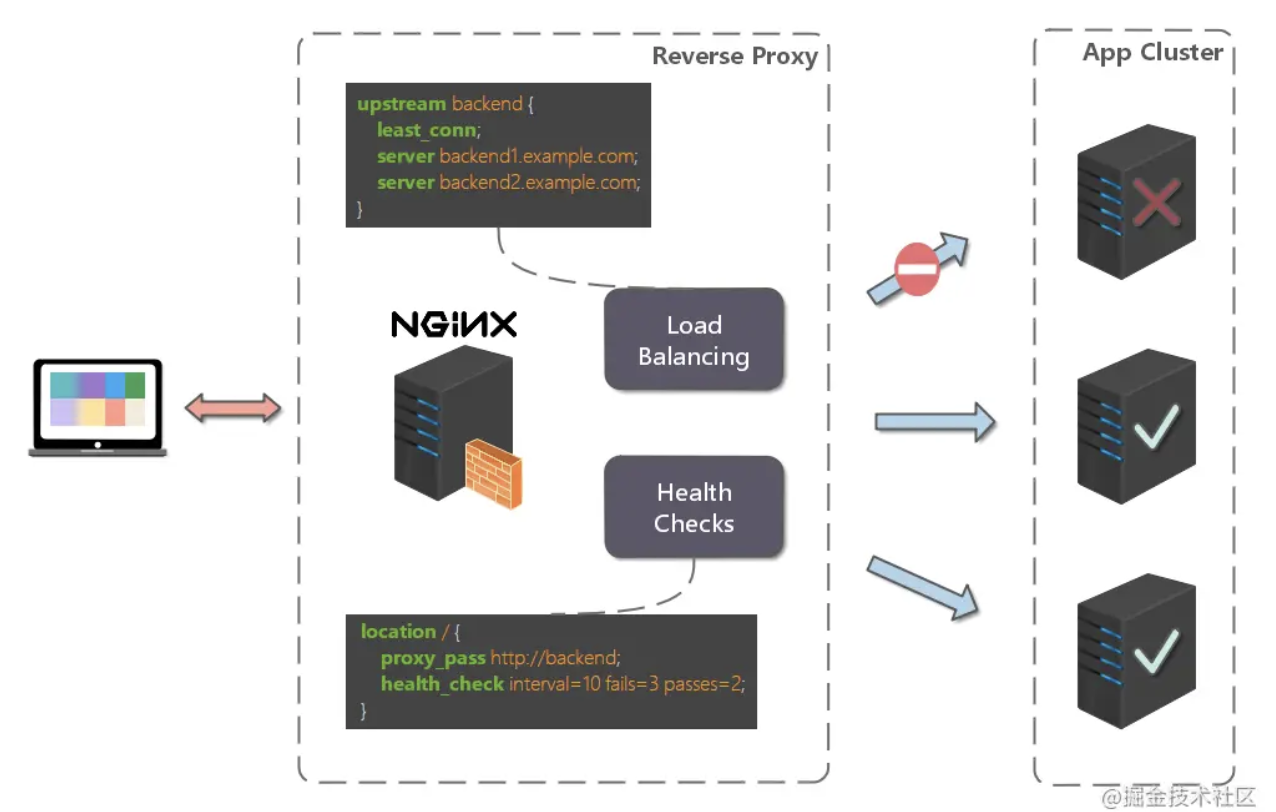
大型网站都要面对庞大的用户量,高并发,海量数据等挑战。为了提升系统整体的性能,可以采用垂直扩展和水平扩展两种方式。
垂直扩展 :通过增加单机硬件的处理能力,比如cpu处理能力,内存容量,磁盘大小等水平扩展 :通过集群来分担流量。集群中的应用服务器被设计成无状态,用户可以请求仍和一个节点,这些节点共同承担访问压力。负载均衡 :就是在水平扩展中尽力将网络流量平均分发到多个服务器上,以提高系统整体的相应速度和可用性。
高并发 :负载均衡通过算法调整负载,尽力均匀的分配应用集群中各节点的工作量,以此提高应用集群的并发处理能力(吞吐量)。伸缩性 :添加或减少服务器数量,然后由负载均衡进行分发控制。这使得应用集群具备伸缩性。高可用 :负载均衡器可以监控候选服务器,当服务器不可用时,自动跳过,将请求分发给可用的服务器。这使得应用集群具备高可用的特性。安全防护 :有些负载均衡软件或硬件提供了安全性功能,如:黑白名单处理、防火墙,防 DDos 攻击等。
正向代理 : 发生在客户端,由用户主动发起的。像翻墙VPN,客户端通过主动访问代理服务器,让代理服务器获得需要的外网数据,然后转发回客户端。反向代理 :发生在服务端,用户对代理无感知。
本文所有代码都参考了负载均衡 | Dubbo Apache
负载均衡接口:
1 2 3 public interface LoadBalance <N extends Node > N select (List<N> nodes, String ip) ; }
负载均衡抽象类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public abstract class BaseLoadBalance <N extends Node > implements LoadBalance <N > @Override public N select (List<N> nodes, String ip) if (CollectionUtil.isEmpty(nodes)) { return null ; } if (nodes.size() == 1 ) { return nodes.get(0 ); } return doSelect(nodes, ip); } protected abstract N doSelect (List<N> nodes, String ip) }
服务器节点类
1 2 3 4 5 6 public class Node implements Comparable <Node > protected String url; protected Integer weight; protected Integer active; }
RandomLoadBalance 是加权随机算法的具体实现,它的算法思想很简单。假设我们有一组服务器 servers = [A, B, C],他们对应的权重为 weights = [5, 3, 2],权重总和为10。现在把这些权重值平铺在一维坐标值上,[0, 5) 区间属于服务器 A,[5, 8) 区间属于服务器 B,[8, 10) 区间属于服务器 C。接下来通过随机数生成器生成一个范围在 [0, 10) 之间的随机数,然后计算这个随机数会落到哪个区间上。比如数字3会落到服务器 A 对应的区间上,此时返回服务器 A 即可。权重越大的机器,在坐标轴上对应的区间范围就越大,因此随机数生成器生成的数字就会有更大的概率落到此区间内。只要随机数生成器产生的随机数分布性很好,在经过多次选择后,每个服务器被选中的次数比例接近其权重比例。比如,经过一万次选择后,服务器 A 被选中的次数大约为5000次,服务器 B 被选中的次数约为3000次,服务器 C 被选中的次数约为2000次。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class WeightRandomLoadBalance <N extends Node > extends BaseLoadBalance <N > implements LoadBalance <N > private final Random random = ThreadLocalRandom.current(); @Override protected N doSelect (List<N> nodes, String ip) int length = nodes.size(); AtomicInteger totalWeight = new AtomicInteger(0 ); for (N node : nodes) { Integer weight = node.getWeight(); totalWeight.getAndAdd(weight); } if (totalWeight.get() > 0 ) { int offset = random.nextInt(totalWeight.get()); for (N node : nodes) { offset -= node.getWeight(); if (offset < 0 ) { return node; } } } return nodes.get(random.nextInt(length)); } }
LeastActiveLoadBalance最小活跃数负载均衡。活跃调用数越小,表明该服务提供这效率越高,单位时间内可处理更多的请求,此时应优先将请求分配给该服务提供这。每个服务提供者对应一个活跃数 active。初始情况下,所有服务提供者活跃数均为0。每收到一个请求,活跃数加1,完成请求后则将活跃数减1。在服务运行一段时间后,性能好的服务提供者处理请求的速度更快,因此活跃数下降的也越快,此时这样的服务提供者能够优先获取到新的服务请求、这就是最小活跃数负载均衡算法的基本思想。
Dubbo在LeastActiveLoadBalance 实现上还引入了权重值。在一个服务提供者集群中,有两个性能优异的服务提供者。某一时刻它们的活跃数相同,此时 Dubbo 会根据它们的权重去随机分配请求,权重越大,获取到新请求的概率就越大。相当于一个加权随机均衡算法嵌套在里面。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 public class LeastActiveLoadBalance <N extends Node > extends BaseLoadBalance <N > implements LoadBalance <N > private final Random random = new Random(); @Override protected N doSelect (List<N> nodes, String ip) int length = nodes.size(); int leastActive = -1 ; int leastCount = 0 ; int [] leastIndexs = new int [length]; int totalWeight = 0 ; int firstWeight = 0 ; boolean sameWeight = true ; for (int i = 0 ; i < length; i++) { N node = nodes.get(i); if (leastActive == -1 || node.getActive() < leastActive) { leastActive = node.getActive(); leastCount = 1 ; leastIndexs[0 ] = i; totalWeight = node.getWeight(); firstWeight = node.getWeight(); sameWeight = true ; } else if (node.getActive() == leastActive) { leastIndexs[leastCount++] = i; totalWeight += node.getWeight(); if (sameWeight && i > 0 && node.getWeight() != firstWeight) { sameWeight = false ; } } } if (leastCount == 1 ) { return nodes.get(leastIndexs[0 ]); } if (!sameWeight && totalWeight > 0 ) { int offsetWeight = random.nextInt(totalWeight); for (int i = 0 ; i < leastCount; i++) { int leastIndex = leastIndexs[i]; offsetWeight -= nodes.get(leastIndex).getWeight(); if (offsetWeight < 0 ) { return nodes.get(leastIndex); } } } return nodes.get(leastIndexs[random.nextInt(leastCount)]); } }
遍历 nodes 列表,寻找活跃数最小的 node
如果有多个 node 具有相同的最小活跃数,此时记录下这些 node 在 nodes 集合中的下标,并累加它们的权重,比较它们的权重值是否相等
如果只有一个 node 具有最小的活跃数,此时直接返回该 Invoker 即可
如果有多个 node 具有最小活跃数,且它们的权重不相等,此时处理方式和 RandomLoadBalance 一致
如果有多个 node 具有最小活跃数,但它们的权重相等,此时随机返回一个即可
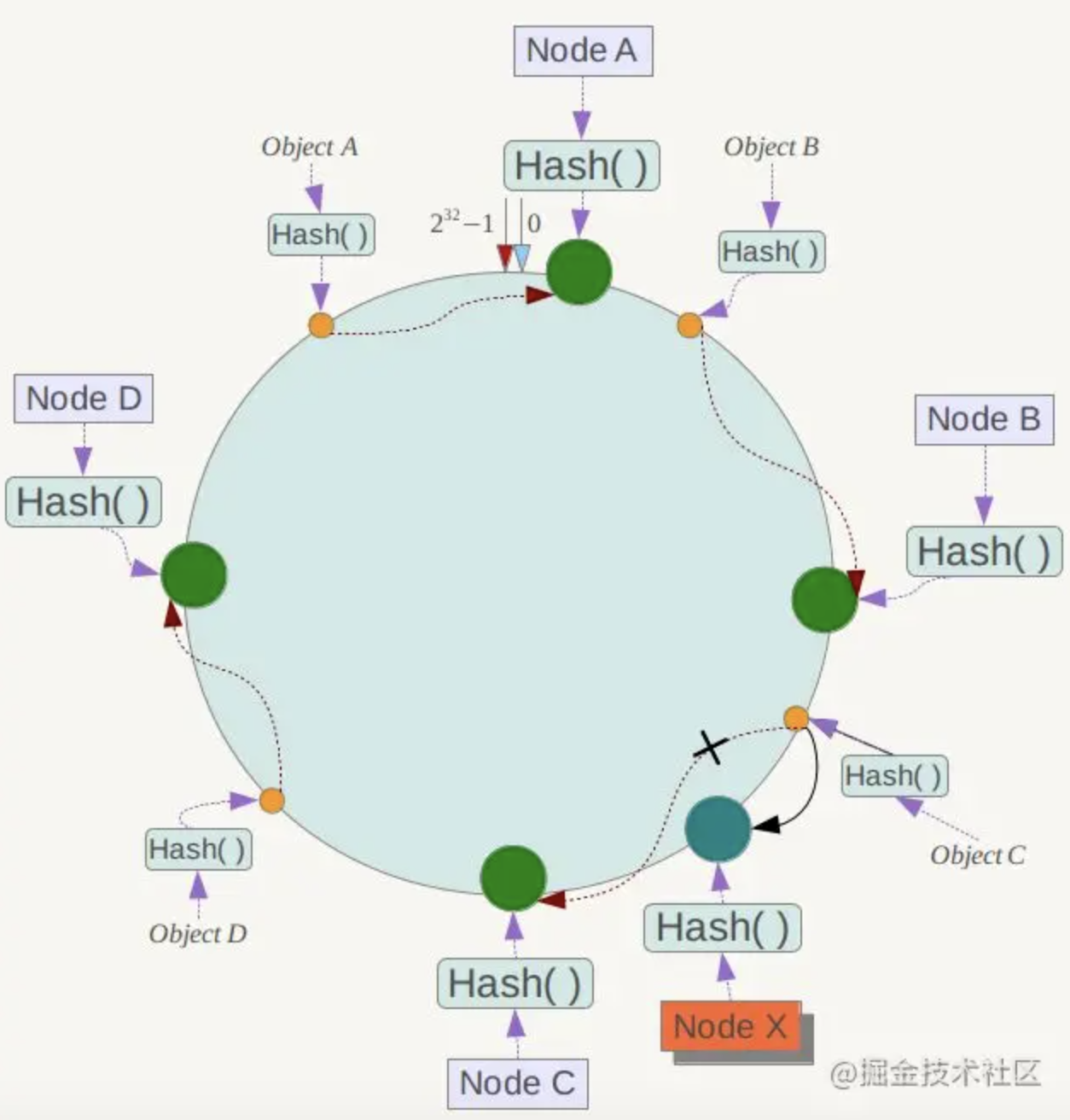
目标:相同的请求尽可能落到同一台服务器上。服务器可能发生上下线,少数服务器的变化不应该影响大多数的请求。
相同的请求的定义:用户id,请求方ip,服务方法名
工作过程:首先根据 ip 或者其他的信息为服务方节点生成一个 hash,并将这个 hash 投射到 [0, 2 32 − 1 2^{32}-1 2 3 2 − 1
优点:如果某个服务方节点挂了,只会影响顺时针方向的相邻节点,对其他节点无影响
缺点:
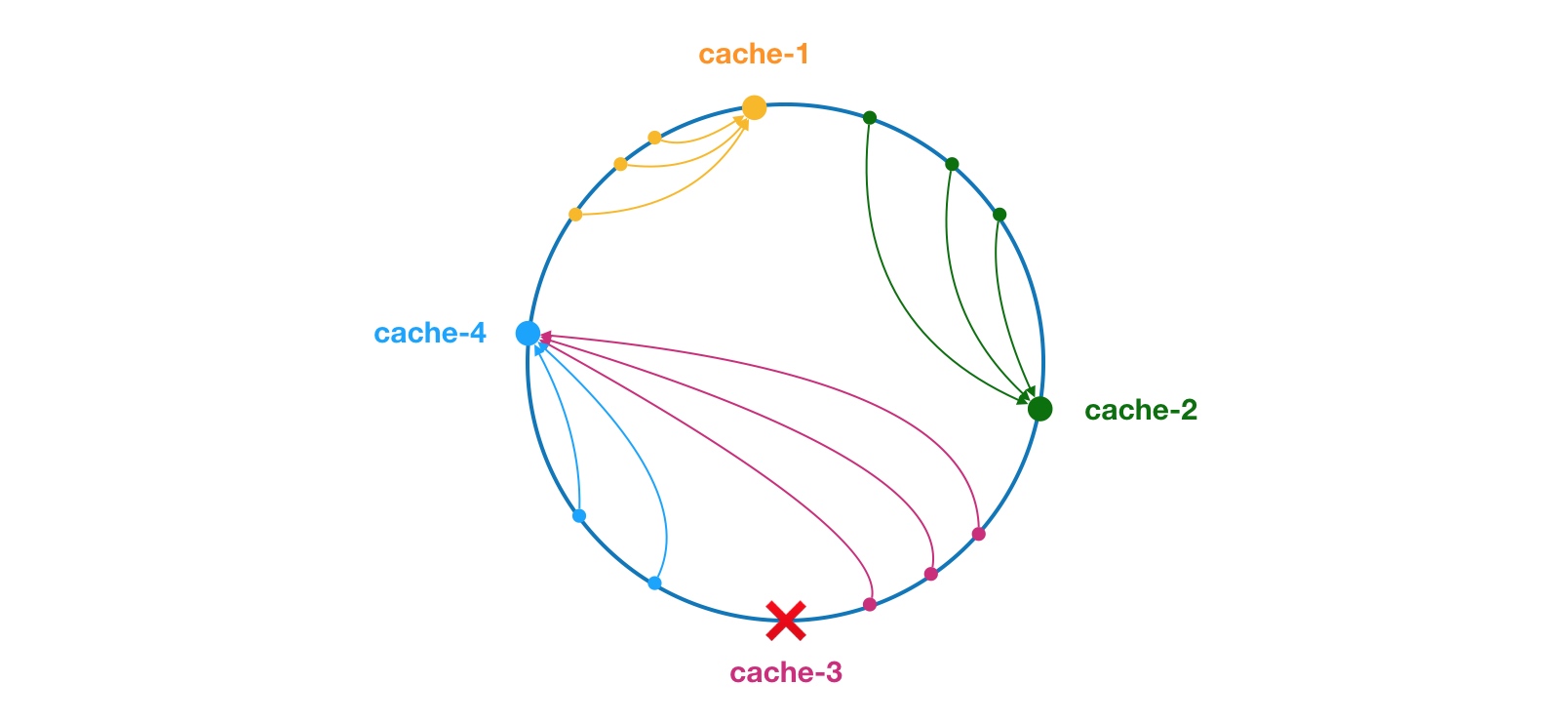
不适合少量数据节点的分布式方案。加减节点会造成哈希环中部分数据无法命中。当使用少量节点时,节点变化将大范围影响哈希环中数据映射。
少量的数据节点会造成数据倾斜
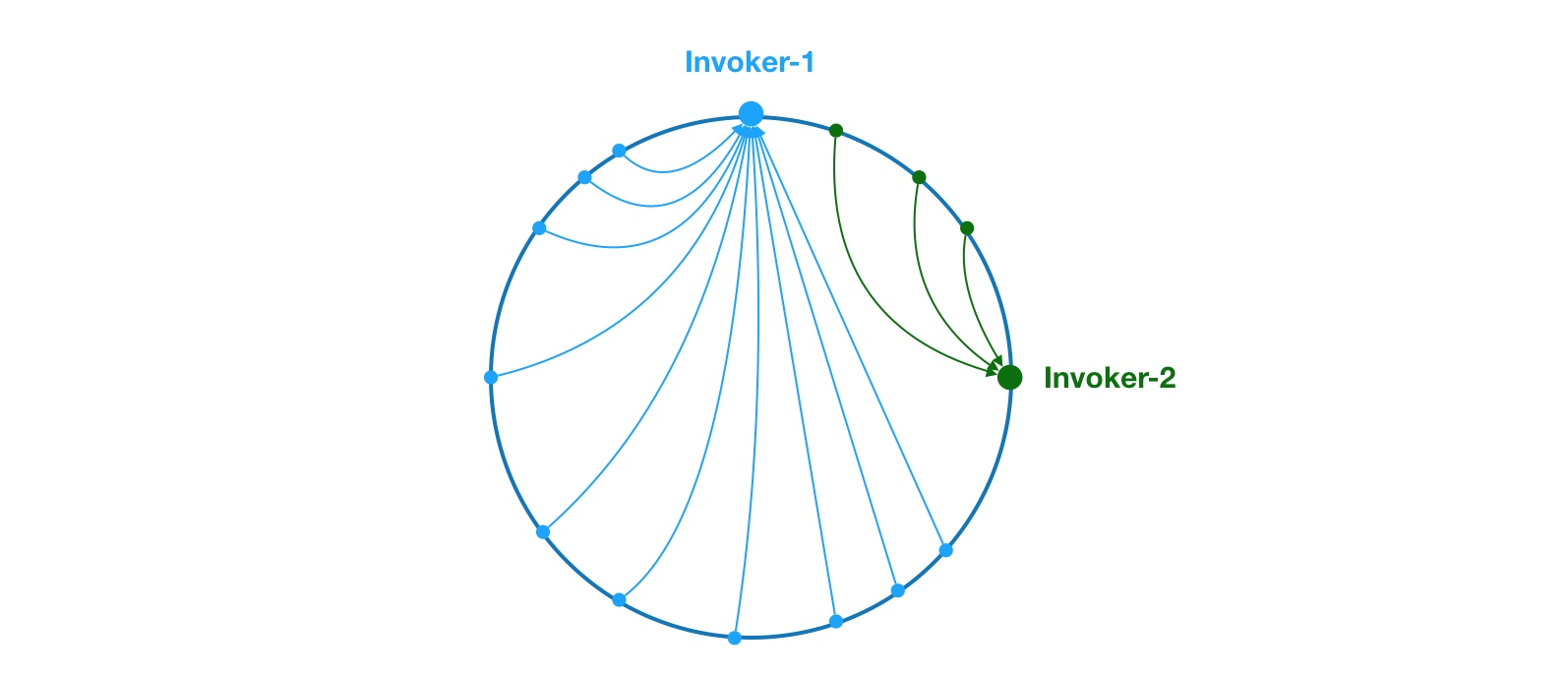
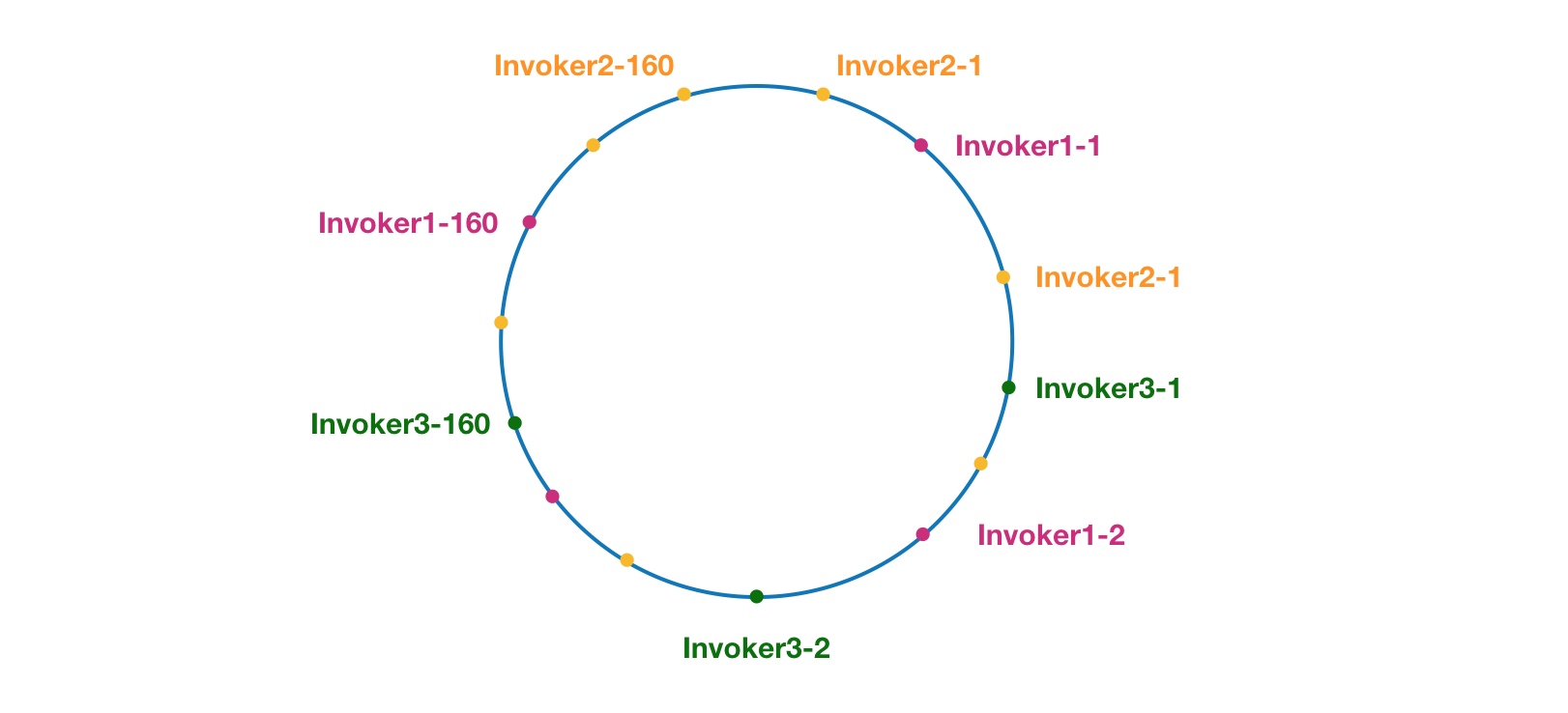
如上,由于 Invoker-1 和 Invoker-2 在圆环上分布不均,导致系统中75%的请求都会落到 Invoker-1 上,只有 25% 的请求会落到 Invoker-2 上。解决这个问题办法是引入虚拟节点,通过虚拟节点均衡各个节点的请求量。
Dubbo的解决方案:通过引入虚拟节点,让 Invoker 在圆环上分散开来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 public class ConsistentHashLoadBalance <N extends Node > extends BaseLoadBalance <N > implements LoadBalance <N > private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap<>(); @SuppressWarnings("unchecked") @Override protected N doSelect (List<N> nodes, String ip) Integer replicaNum = nodes.size() * 4 ; int identityHashCode = System.identityHashCode(nodes); ConsistentHashSelector<N> selector = (ConsistentHashSelector<N>) selectors.get(ip); if (selector == null || selector.identityHashCode != identityHashCode) { selectors.put(ip, new ConsistentHashSelector<>(nodes, identityHashCode, replicaNum)); selector = (ConsistentHashSelector<N>) selectors.get(ip); } return selector.select(ip); } private static final class ConsistentHashSelector <N extends Node > private final TreeMap<Long, N> virtualNodes; private final int identityHashCode; ConsistentHashSelector(List<N> nodes, int identityHashCode, Integer replicaNum) { this .virtualNodes = new TreeMap<>(); this .identityHashCode = identityHashCode; if (replicaNum == null ) { replicaNum = 100 ; } for (N node : nodes) { for (int i = 0 ; i < replicaNum / 4 ; i++) { byte [] digest = md5(node.getUrl()+i); for (int j = 0 ; j < 4 ; j++) { long m = hash(digest, j); virtualNodes.put(m, node); } } } } public N select (String key) byte [] digest = md5(key); return selectForKey(hash(digest, 0 )); } private N selectForKey (long hash) Map.Entry<Long, N> entry = virtualNodes.ceilingEntry(hash); if (entry == null ) { entry = virtualNodes.firstEntry(); } return entry.getValue(); } } public static long hash (byte [] digest, int number) return (((long ) (digest[3 + number * 4 ] & 0xFF ) << 24 ) | ((long ) (digest[2 + number * 4 ] & 0xFF ) << 16 ) | ((long ) (digest[1 + number * 4 ] & 0xFF ) << 8 ) | (digest[number * 4 ] & 0xFF )) & 0xFFFFFFFFL ; } public static byte [] md5(String value) { MessageDigest md5; try { md5 = MessageDigest.getInstance("MD5" ); } catch (NoSuchAlgorithmException e) { throw new IllegalStateException(e.getMessage(), e); } md5.reset(); byte [] bytes = value.getBytes(StandardCharsets.UTF_8); md5.update(bytes); return md5.digest(); } }
从最简单的轮询开始讲起,所谓轮询是指将请求轮流分配给每台服务器。举个例子,我们有三台服务器 A、B、C。我们将第一个请求分配给服务器 A,第二个请求分配给服务器 B,第三个请求分配给服务器 C,第四个请求再次分配给服务器 A。这个过程就叫做轮询。轮询是一种无状态负载均衡算法,实现简单,适用于每台服务器性能相近的场景下。但现实情况下,我们并不能保证每台服务器性能均相近。如果我们将等量的请求分配给性能较差的服务器,这显然是不合理的。因此,这个时候我们需要对轮询过程进行加权,以调控每台服务器的负载。经过加权后,每台服务器能够得到的请求数比例,接近或等于他们的权重比。比如服务器 A、B、C 权重比为 5:2:1。那么在8次请求中,服务器 A 将收到其中的5次请求,服务器 B 会收到其中的2次请求,服务器 C 则收到其中的1次请求。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 public class WeightedRoundRobin extends AbstractLoadBalance private final ConcurrentMap<String, AtomicPositiveInteger> sequences = new ConcurrentHashMap<String, AtomicPositiveInteger>(); @Override protected Node doSelect (List<Node> nodes, String ip) int length = nodes.size(); int maxWeight = 0 ; int minWeight = Integer.MAX_VALUE; final LinkedHashMap<Node, Integer> invokerToWeightMap = new LinkedHashMap<Node, Integer>(); int weightSum = 0 ; String key = "test" ; for (int i = 0 ; i < length; i++) { int weight = nodes.get(i).getWeight(); maxWeight = Math.max(maxWeight, weight); minWeight = Math.min(minWeight, weight); if (weight > 0 ) { invokerToWeightMap.put(nodes.get(i), weight); weightSum += weight; } } AtomicPositiveInteger sequence = sequences.get(key); if (sequence == null ) { sequences.putIfAbsent(key, new AtomicPositiveInteger()); sequence = sequences.get(key); } int currentSequence = sequence.getAndIncrement(); if (maxWeight > 0 && minWeight < maxWeight) { int mod = currentSequence % weightSum; for (int i = 0 ; i < maxWeight; i++) { for (Map.Entry<Node, Integer> each : invokerToWeightMap.entrySet()) { Node k = each.getKey(); Integer v = each.getValue(); if (mod == 0 && v > 0 ) { return k; } if (v > 0 ) { v--; invokerToWeightMap.put(k, v); mod--; } } } } return nodes.get(currentSequence % length); } }
下面我们举例进行说明,假设我们有三台服务器 servers = [A, B, C],对应的权重为 weights = [2, 5, 1]。接下来对上面的逻辑进行简单的模拟。
mod = 0:满足条件,此时直接返回服务器 A: [2,5,1]
mod = 1:需要进行一次递减操作才能满足条件,此时返回服务器 B: [2,5,1] [1,5,1]
mod = 2:需要进行两次递减操作才能满足条件,此时返回服务器 C: [2,5,1] [1,5,1] [1,4,1]
mod = 3:需要进行三次递减操作才能满足条件,此时返回服务器 A: [2,5,1] [1,5,1] [1,4,1] [1,4,0]
mod = 4:需要进行四次递减操作才能满足条件,此时返回服务器 B: [2,5,1] [1,5,1] [1,4,1] [1,4,0] [0,4,0]
mod = 5:需要进行五次递减操作才能满足条件,此时返回服务器 B: [2,5,1] [1,5,1] [1,4,1] [1,4,0] [0,4,0] [0,3,0]
mod = 6:需要进行六次递减操作才能满足条件,此时返回服务器 B: [2,5,1] [1,5,1] [1,4,1] [1,4,0] [0,4,0] [0,3,0] [0,2,0]
mod = 7:需要进行七次递减操作才能满足条件,此时返回服务器 B: [2,5,1] [1,5,1] [1,4,1] [1,4,0] [0,4,0] [0,3,0] [0,2,0] [0,1,0]
以上是 2.6.4 版本的 RoundRobinLoadBalance 分析过程,2.6.4 版本的 RoundRobinLoadBalance 在某些情况下存在着比较严重的性能问题。问题出在了 Invoker 的返回时机上,RoundRobinLoadBalance 需要在mod == 0 && v.getValue() > 0 条件成立的情况下才会被返回相应的 Invoker。假如 mod 很大,比如 10000,50000,甚至更大时,doSelect 方法需要进行很多次计算才能将 mod 减为0。由此可知,doSelect 的效率与 mod 有关,时间复杂度为 O(mod)。mod 又受最大权重 weightSum 的影响,因此当某个服务提供者配置了非常大的权重,此时 RoundRobinLoadBalance 会产生比较严重的性能问题。
总而言之,这一版的算法可以看做模拟整个轮询过程,也就是说当mod=7的时候,我还经历了一遍0~6的分配过程才拿到7的分配结果。显然时间复杂度变为O(weightedSum),非常影响性能。
优化一:减小时间复杂度
这版的算法不和上一版一样,为了拿第8次的分配还要走一遍前7次。通过增加一个属性indexSeqs来记录这一次的分配结果,这样在下一次分配的时候就直接从上一次分配结果开始,这样只要经过O(nodes.size)就可以得到结果了。
下面举例说明,假设服务器 [A, B, C] 对应权重 [5, 2, 1]。
第一次请求,currentWeight = 1,index=0,A: [5>1,2,1]
第二次请求,currentWeight = 1,index=1,B: [5,2$\gt$1,1]
第三次请求,currentWeight = 1/2,index=2/0,A: [5,1,1$\ngtr$1] [5>2,1,1]
第四次请求,currentWeight = 2/2/3,index=1/2/0,A: [5,1$\ngtr2 , 1 ] [ 5 , 1 , 1 2,1] [5,1,1 2 , 1 ] [ 5 , 1 , 1
第五次请求,currentWeight = 3/3/4,index=1/2/0,A: [5,1$\ngtr3 , 1 ] [ 5 , 1 , 1 3,1] [5,1,1 3 , 1 ] [ 5 , 1 , 1
第六次请求,currentWeight = 4/4/0,index=1/2/0,A: [5,1$\ngtr4 , 1 ] [ 5 , 1 , 1 4,1] [5,1,1 4 , 1 ] [ 5 , 1 , 1
第七次请求,currentWeight = 0,index=1,B: [5,1$\gt$0,1]
第八次请求,currentWeight = 0,index=2,C: [5,1,1$\gt$0]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 public class RoundRobinLoadBalance extends AbstractLoadBalance public static final String NAME = "roundrobin" ; private final ConcurrentMap<String, AtomicPositiveInteger> sequences = new ConcurrentHashMap<String, AtomicPositiveInteger>(); private final ConcurrentMap<String, AtomicPositiveInteger> indexSeqs = new ConcurrentHashMap<String, AtomicPositiveInteger>(); @Override protected Node doSelect (List<Node> nodes, String ip) int length = nodes.size(); int maxWeight = 0 ; int minWeight = Integer.MAX_VALUE; final Map<Node, Integer> invokerToWeightMap = new HashMap<>(); for (int i = 0 ; i < length; i++) { int weight = nodes.get(i).getWeight(); maxWeight = Math.max(maxWeight, weight); minWeight = Math.min(minWeight, weight); invokerToWeightMap.put(invokers.get(i), weight); } AtomicPositiveInteger sequence = sequences.get(key); if (sequence == null ) { sequences.putIfAbsent(key, new AtomicPositiveInteger()); sequence = sequences.get(key); } AtomicPositiveInteger indexSeq = indexSeqs.get(key); if (indexSeq == null ) { indexSeqs.putIfAbsent(key, new AtomicPositiveInteger(-1 )); indexSeq = indexSeqs.get(key); } if (maxWeight > 0 && minWeight < maxWeight) { length = invokerToWeightList.size(); while (true ) { int index = indexSeq.incrementAndGet() % length; int currentWeight = sequence.get() % maxWeight; if (index == 0 ) { currentWeight = sequence.incrementAndGet() % maxWeight; } if (invokerToWeightMap.get(index) > currentWeight) { return nodes.get(index); } } } return nodes.get(sequence.incrementAndGet() % length); } }
优化二:平滑处理
在某些情况下选出的服务器序列不够均匀。比如,服务器 [A, B, C] 对应权重 [5, 1, 1]。进行7次负载均衡后,选择出来的序列为 [A, A, A, A, A, B, C]。前5个请求全部都落在了服务器 A上,这将会使服务器 A 短时间内接收大量的请求,压力陡增。而 B 和 C 此时无请求,处于空闲状态。而我们期望的结果是这样的 [A, A, B, A, C, A, A],不同服务器可以穿插获取请求。为了增加负载均衡结果的平滑性,Dubbo社区再次对 RoundRobinLoadBalance 的实现进行了重构,这次重构参考自 Nginx 的平滑加权轮询负载均衡。每个服务器对应两个权重数组,分别为 weight 和 currentWeight。其中 weight 是固定的,currentWeight 会动态调整,初始值为0。当有新的请求进来时,遍历服务器列表,让它的 currentWeight 加上自身权重。遍历完成后,找到最大的 currentWeight,并将其减去权重总和,然后返回相应的服务器即可。
请求编号
currentWeight 数组
选择结果
最大entry减去权重总和后的currentWeight数组
1
[5, 1, 1]
A
[-2, 1, 1]
2
[-2, 1, 1]+[5,1,1]=[3, 2, 2]
A
[-4, 2, 2]
3
[-4, 2, 2]+[5,1,1]=[1, 3, 3]
B
[1, -4, 3]
4
[1, -4, 3]+[5,1,1]=[6, -3, 4]
A
[-1, -3, 4]
5
[-1, -3, 4]+[5,1,1]=[4, -2, 5]
C
[4, -2, -2]
6
[4, -2, -2]+[5,1,1]=[9, -1, -1]
A
[2, -1, -1]
7
[2, -1, -1]+[5,1,1]=[7, 0, 0]
A
[0, 0, 0]
这样平滑处理后的算法依然能维持时间复杂度O(nodes.size)。