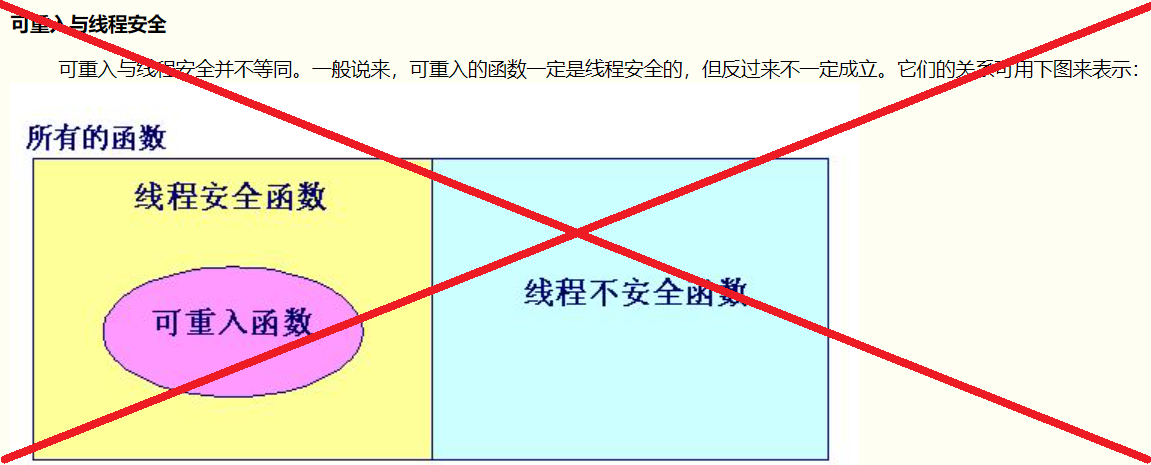
在百度搜索关键词"可重入和线程安全"跳出来的第一篇被抄来抄去的博客堂而皇之地写道“可重入函数一定是线程安全的”,还煞有介事地画了一张图。但实际上,Wikipedia的词条Reentrancy(computing)上非常清楚地说明了二者不存在任何充分必要条件。
A reentrant subroutine can achieve thread-safety, but being reentrant alone might not be sufficient to be thread-safe in all situations. Conversely, thread-safe code does not necessarily have to be reentrant.
辨析
实际上,可重入性(Reentrancy)和线程安全(Thread-safety)是针对两个不同的场景。可重入性针对的是单线程下由于中断导致临界资源发生改变而使得和不中断时的执行结果不一致;而线程安全问题更多的是强调多线程、多处理器情况下对临界资源的竞争、修改导致的每次执行结果不一致的问题。
- 可重入的概念比线程安全的概念更早被重视,在多任务系统出现以前就被提出
- 可重入和线程安全不等价,一般情况下可重入的函数是线程安全的,但是可重入的要求会比线程安全更加严格
- 需要注意的是,二者都是对某一段代码(函数)的设计进行考虑,也就是说在不同调用者在任何时间内执行统一块代码时是否会出现超出预期的结果
贴下Wiki定义
Reentrancy
A reentrant procedure can be interrupted in the middle of its execution and then safely be called again (“re-entered”) before its previous invocations complete execution. The interruption could be caused by an internal action such as a jump or call, or by an external action such as an interrupt or signal.
定义可重入性最关键的就是在函数执行的过程中被打断然后能够重新调用该函数并且不会影响这次以及上一次调用的预期结果。所以什么时候我们需要考虑一个函数的可重入性? 当我们的函数被设计成允许中断并被重新执行时,我们就需要考虑这个函数的可重入性。什么样的场景会出现需要设计成可重入的函数? 我能想到的场景是当同一个执行流DAG有多个实例但却只能是单进程执行且允许中断的情况下需要考虑可重入性。
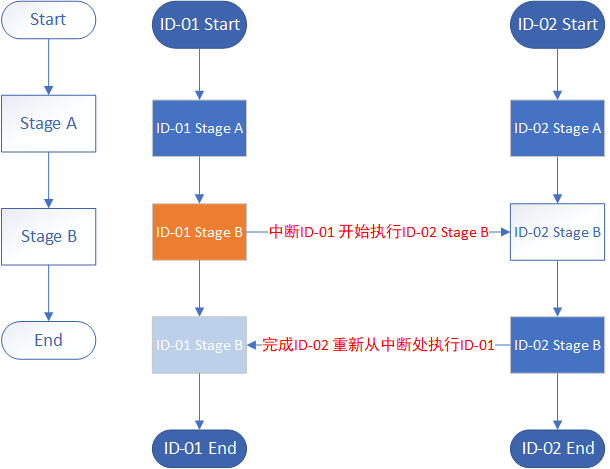
如上图同一个DAG执行流(比如处理数据要经过的步骤,或者事件流之类的),在同一时段起了两个执行实例,但是处理器(可以是进程或者线程)只有一个,当处理器在处理一个实例中的某个节点时,用户向这个实例发送了中断命令,处理器停止处理ID-01实例的Stage B节点处理,转而处理ID-02实例的Stage B节点,处理的代码都是一致的。此时我们便需要考虑这样的代码重入会不会影响两个实例各自的Stage B处理结果。
Thread-safety
Thread-safe code only manipulates shared data structures in a manner that ensures that all threads behave properly and fulfill their design specifications without unintended interaction.
在讨论线程安全之前我们需要想好我们的函数想要实现什么样的功能,多线程的引入是否会带来超出预期的结果。比如对于一个HashMap的操作,如果只有多线程的并发读那么显然不会有任何线程安全问题,但是如果各个线程中会对这个临界数据结构进行写操作,我们就必须考虑原子性、可见性、有序性等一系列会造成超出预期结果的问题。
例子
下面用四个例子来帮助我们辨析可重入性和线程安全的差别。有一个swap函数来表示我们要考虑可重入性的函数,isr函数作为interrupt subroutine handler来处理swap被中断后的操作。考虑可重入时,要考虑第一次swap被中断后isr的第二次重新调用;考虑线程安全时,要考虑同一个函数swap被多个线程调用的场景。
既不是可重入又不是线程安全
1 | int tmp; |
就可重入性而言,swap使用的是全局变量tmp,但它运行被interrupt出去后,isr重新调用swap将会重新改写tmp的值而使得第一次swap的输出不再符合原来的逻辑。同时显而易见,线程不安全。
线程安全但不是可重入
1 | _Thread_local int tmp; |
就可重入性而言,单线程情况下依然会出现初次调用的tmp被isr更改。而在多线程情况下,由于tmp是thread local,所以做到了线程安全。
可重入但不是线程安全
1 | int tmp; |
非常有意思的例子,在wiki中的描述是somewhat contrived,但在实践上这样的函数(实现reetrant但不thread safe)基本是毫无意义的。我们可以看到在swap中将共有变量进行了一次复制,也就使得在这个函数结束的时候swap的值是保持不变的,当第一次swap被interrupt后,isr再次进入swap虽然会临时改动tmp,但是只要最后isr完成了到了最后一步将tmp恢复成原样,那么结束interrupt时第一次swap依然能正常执行并产出符合预期的结果。也就是说在这样的情况下即使递归地被interrupt,只要最后一次递归的swap完成了swap的所有操作,那么先前的swap操作都能够正常执行。因此,它是可重入的。然而如果是多线程,因为说到底是对公用变量的修改,因此不加锁是线程不安全的。
可重入又线程安全
1 | void swap(int* x, int* y) |
所有的变量都是本地变量,没有共有变量,多线程各个栈之间是隔离的,所以既是可重入又是线程安全。
隔了几天,为了写这篇blog重新翻了下wiki,发现又多了几个例子来解释为啥可以thread-safe但不是reentrant,并且还被打上了multiple issues的标签。可见大伙儿对二者的区分还是有许多不同意见啊。
可重入锁
在这里我们直讲如何理解可重入锁中的可重入性,更细节的锁设计会在之后的博客给出(挖坑)。
很多时候我们在使用锁的时候没有考虑过它的可重入性主要是因为大多场景我们都希望是可重入的。所以为了明白什么是可重入我们必须得了解什么是不可重入。
假设下列伪代码是我们使用锁的场景,也就是有多个函数共用一把锁,并且会递归地对锁进行操作。现在我们要对Lock这个类进行设计。
1 | public class Test { |
用自旋的方式设计成不可重入的锁:
1 | public class Lock{ |
如果用这样的方式去执行Test中的代码即使是单线程也同样会出现A被永远阻塞的情况。因为它递归地调用了B而B的操作需要重新进入lock()拿到这把锁的所有权,而这把锁却是在A手上所以B将永远拿不到形成死锁。因此,我们希望在单线程下,能够递归地对锁进行加锁和解锁的操作。
可重入锁的实现方式:
1 | public class Lock{ |
首先,代码的核心在于锁已有主的情况下弄清谁在试图拿到这把锁,只有判断试图加锁的线程和目前持有该锁的线程为同一线程时才会考虑可重入。不是同一线程自然不能拿到锁权,毕竟lock的基本要求是满足线程安全。在同一线程下的所有加锁操作都不会形成阻塞,而是在lockCount上去进行自增来标记目前有多少个lock()调用,而在unlock()时便会去对lockCount进行减一,只有当这个线程下所有对锁的调用都完成之后也就是lockCount归位0后,才算结束改线程对这个临界资源的占用。因此,在使用这样的可重入锁时,Test的执行才不会出现死锁的情况。
可重入锁和可重入性到底什么关系?
可重入锁似乎和前面讲的单线程可重入性没有关系,没有地方可以看到有函数被设计成会被打断。然而实际上对锁进行lock()然后再执行自定义的代码然后再unlock()就是一种interruption。我们可以把lock()和unlock()看作是一个函数,因为对锁的任何操作都必须经过这两个步骤,而执行临界代码实际上就是在
1 | lock(); |
中间打断然后执行自定义的isr()。因此我们才需要在设计锁的时候考虑可重入性。