作为Google大数据时代三架马车之一的Bigtable: A Distributed Storage System for Structured Data,其中的理念,模型和设计思想依然影响着许多当下大型数据库的设计。不过,作为一个经受过无数业务考验的大数据产品,其背后细致入微的工程设计是无法完全在论文、博客中得以体现的。笔者作为一个刚入门大数据领域不久的新人,在工作当中时常会接触到HBase(Bigtable的开源实现),便想读一读这篇经典的论文,记录下阅读和查找资料过程当中的思考,尚不曾仔细地研究过一些开源项目。希望未来能在参与一点相关的工作过后能有更深刻的理解。
Bigtable的适用场景
- 写密集型应用:写入量大但是随机读的量相对较小
- 海量数据的持久化:网页搜索引擎需要存储大量的网页信息,并且这些信息在持续不断地更新,所以Bigtable不仅要及时存储当前的消息还需要保证历史信息的持久化
- 不要复杂的查询逻辑:没有join(代价很大),没有SQL,只在基于rowkey, timestamp, column name的查询上有较好的性能
- 可靠性高:无单点故障,高可用
- 高可伸缩性:数据量增长时能够及时横向扩展
- 数据局部性(locality)要求:希望相似的数据能够存一起,提高压缩和吞吐
在笔者的工作实践中经常会有需要不同Hbase表进行join的场景,这些场景我们会使用Flink作为执行引擎去调用
Bigtable不是什么?
Bigtable不是关系型数据库,不支持事务性操作,不支持SQL,不提供完整的关系型数据模型,没有数据类型,严格来讲不是列存而是面向列簇的行存。
Bigtable是什么?
Bigtable 是一种压缩的、高性能的、高可扩展性的,基于 Google 文件系统(Google File System,GFS)的数据存储系统,用于存储PB级结构化数据。支持用户动态控制数据的分布和格式。支持用户推断数据的locality property。
Bigtable的数据模型
A Bigtable is a sparse, distributed, persistent multi-dimensional sorted map.
Bigtable的数据模型就是以row id, column name, timestamp的联合组成作为key的有序map。如果对比与关系型数据库,它的每一行组成并没有预先设置的结构而是sparse的。也就是说即使在同一张表的同一个column family下,每一行数据的column也不尽相同。
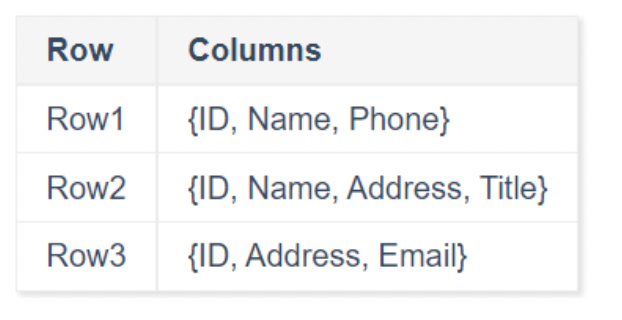
同时,整个map将按照{rowkey, column key, timestamp}进行排序。
例子
论文中举了一个网页存储的例子。
Webtable: 存储网页。rowkey是反转的URL,contents和anchor都是一个列族(column family),contents列族存网页信息,网页属性为列名;anchor列族存其他网站的引用,其他引用过的网站为列名。一个列族下可以有任意个列。为了存储网页的历史信息,写入表中的所有值都会自带时间戳,也就是说一个值会有不同的时间版本。
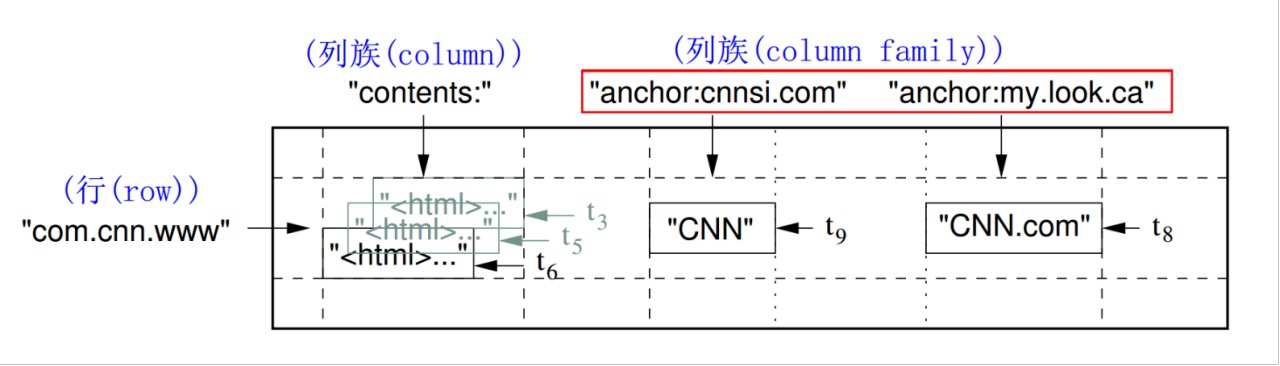
术语
Rowkey:
- Rowkey是任意字符串上限是64KB
- 每个行键下所包含的数据的读或写都是一个原子操作,不管这个行中所包含的列的数量是多少
- 按照rowkey的字典序存储数据
Tablet:
- 进行动态划分的,连续的rowkey行区间,可以利用这个特性来设计数据局部性(locality)
- Bigtable数据分布和负载均衡的最小单位
- 最初每张表都只有1个tablet,当tablet的大小增长时,tablet就会分裂成多个tablet,每个默认大小为100-200MB
Column Family:
- 多个column key的集合,access control和磁盘内存审计的基本单位
- 需要在创建column之前先定好column family,属于表的结构
- 每个表中的column family数量是确定的,而column的数量可以是不定的
同一个column family的数据将被一起压缩
为什么HBase(Bigtable)不算列存?
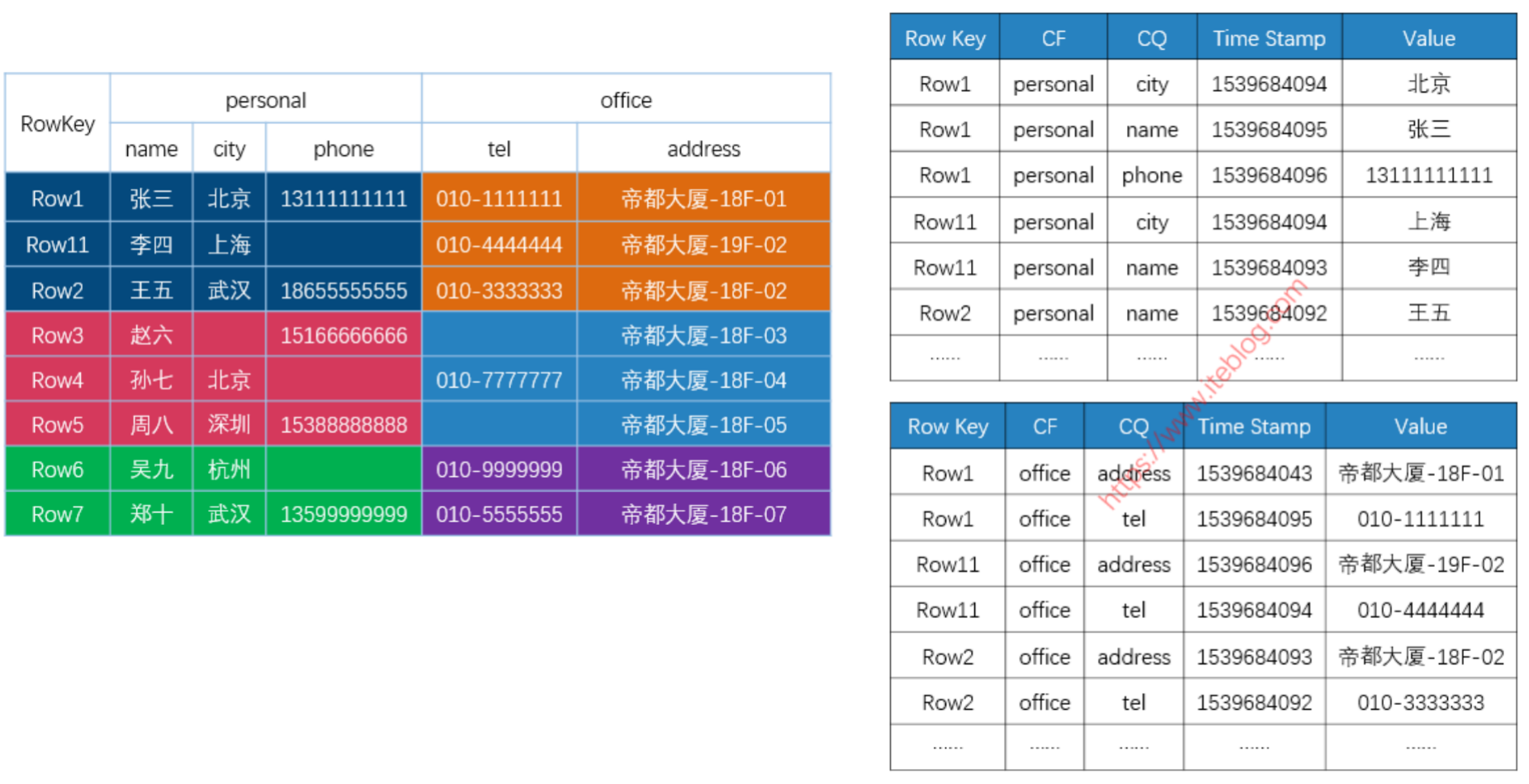
左图是逻辑上Bigtable存储数据的方式,而右图则是物理上存储log在SSTable上的。我们可以看到除了不同的column family会存储在不同的SSTable上,同一个SSTable下的各个record还是按照行存的方式,所以说BigTable不是列存而是面向列簇的存储。
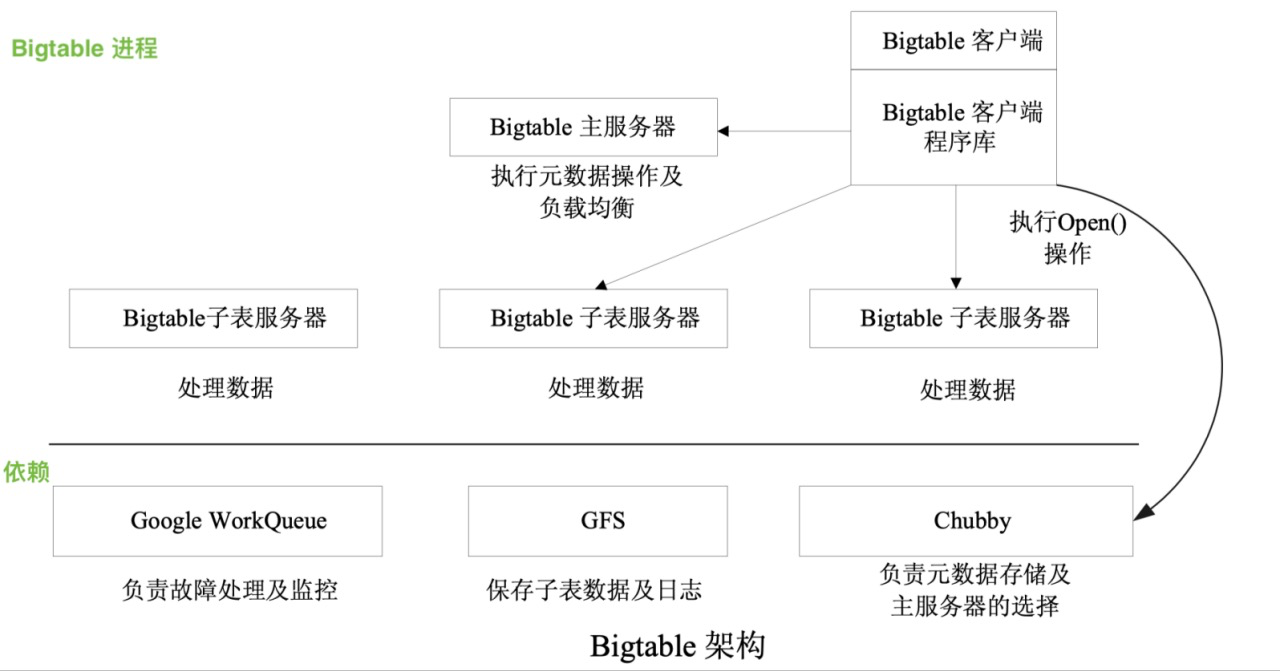
BigTable的架构
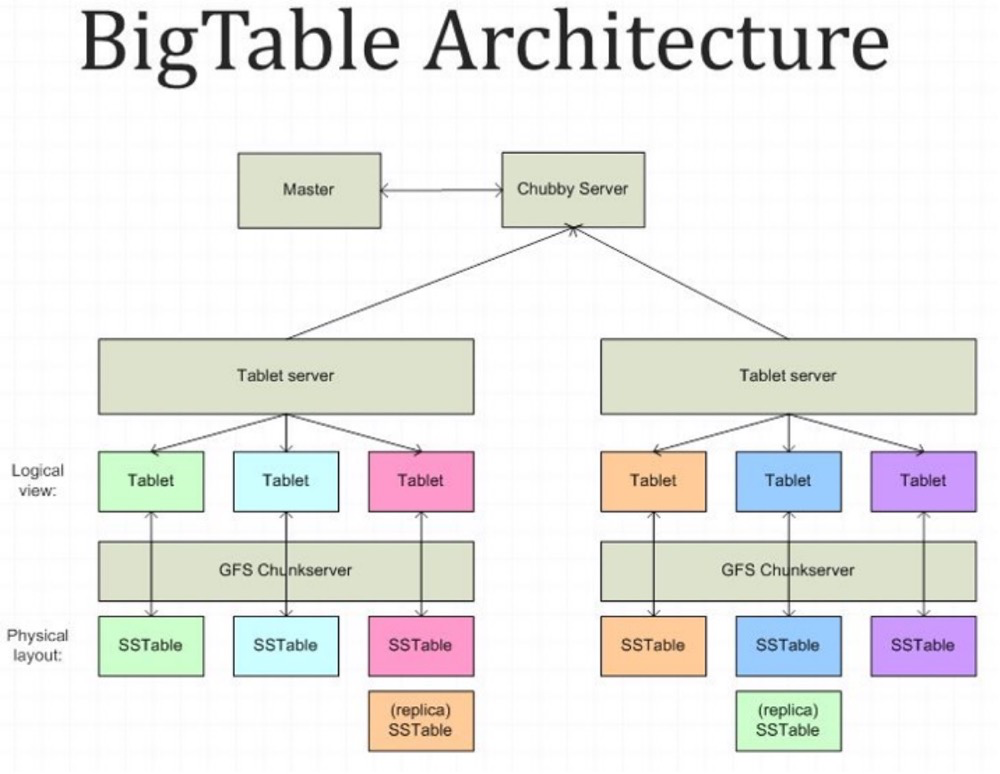
Chubby: Hbase中的ZK,分布式锁,Master选举
Master: 为tablet server分配tablet, 检测tablet server的加入或过期, 从chubby中同步tablet server的元数据,tablet的分配情况, 表结构管理
GFS: Hbase中的HDFS,底层分布式文件系统
Tablet Server: Hbase中的region server, 每个tablet server管理一组tablet, 负责直接和客户端进行交互进行读写操作, 减轻master负载
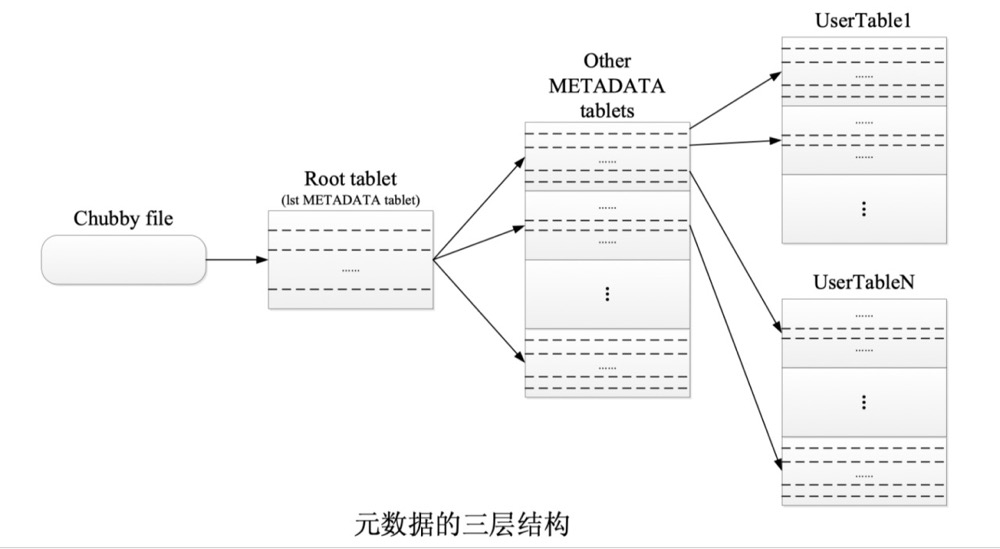
Tablet的定位
Bigtable 使用三层类 B+ 树结构来存储元数据信息。第一层是存储在 Chubby 中的根子表,根子表是元数据(METADATA)表的第一个子表。根子表包含了所有元数据子表的位置信息,元数据子表包含一组用户子表的位置信息。在元数据的三级结构中,根子表不会被分割,用于确保子表的层次结构不超过三层。由于元数据行大约存储 1KB 的内存数据,在容量限制为 128MB 内的元数据子表中,三层模型可以标识 234 个子表。
Hbase在0.96.0版本之前采用的也是bigtable的三层索引结构,之后的版本采用两层索引,去掉了root表直接将metadata的地址存在zookeeper中
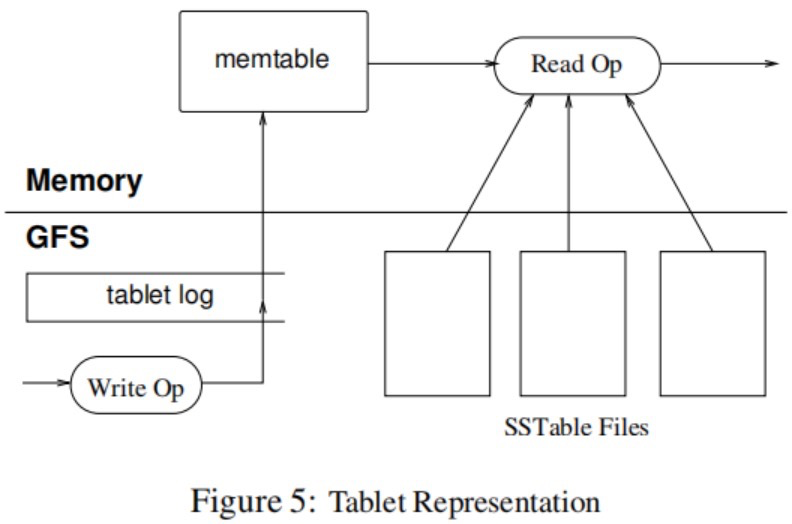
IO
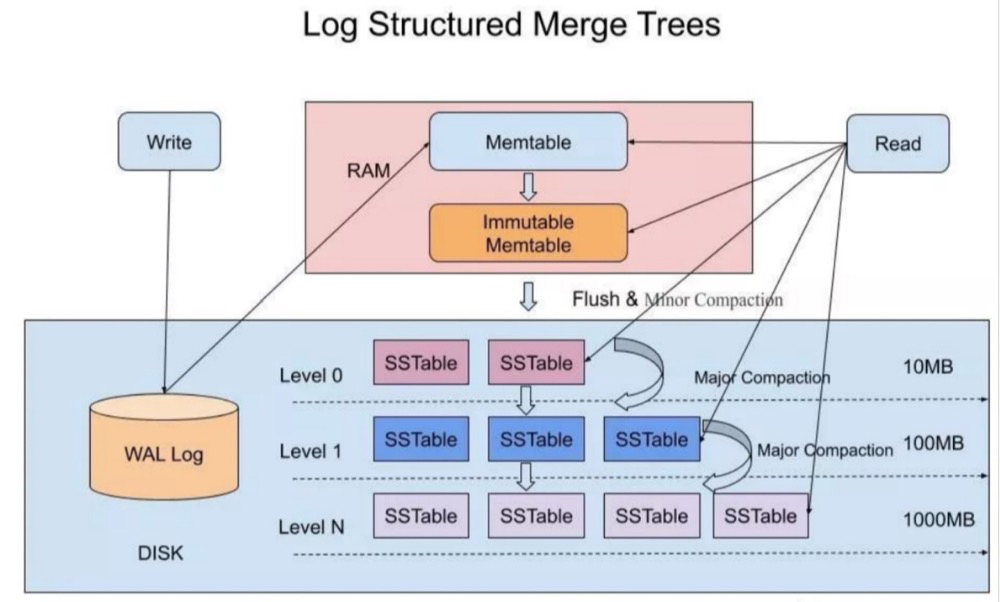
BigTable实际上是LSM(Log-Structured Merged Tree)的分布式实现,所以它IO的整个流程都是按照LSM的方式去进行的。
写操作:首先写入也存储于log(WAL)文件中(磁盘),然后写入内存中的 Memtable。此时写操作对于客户端来说已经结束了,Memtable会在达到阈值时flush数据到SSTable中。
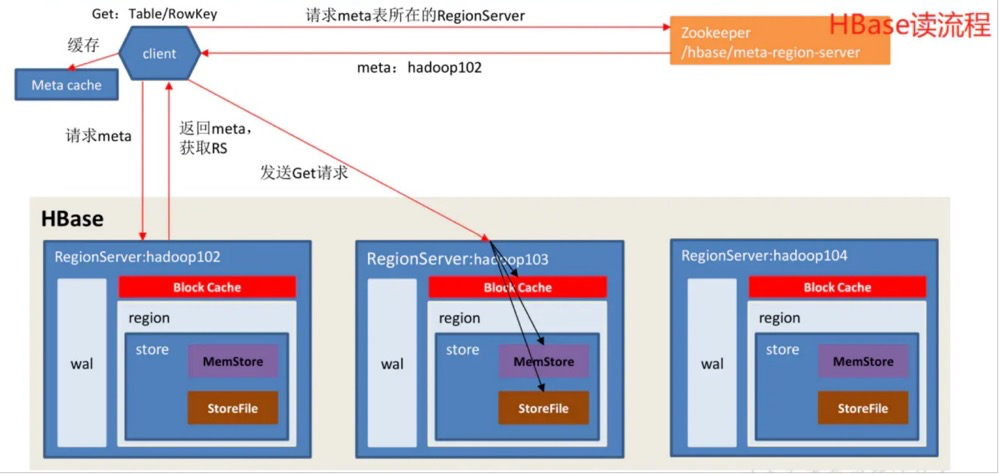
读操作:一个有效的读操作在一个由一系列SSTable和memtable合并的view里执行的。由于SSTable和memtable是按字典排序的数据结构,因此可以高效生成合并view。
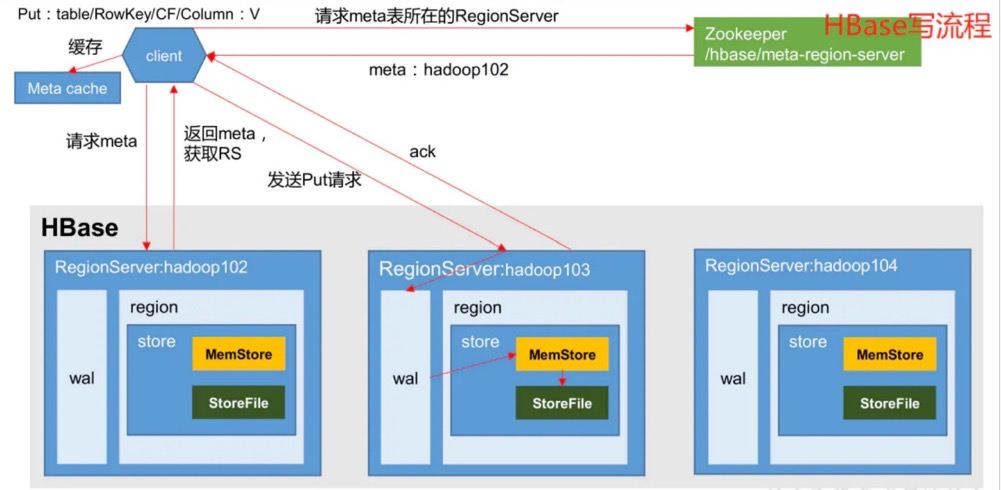
更细致的读写可以参考下列HBase的实现:
Compaction
Minor Compaction: 当MemTable占用的内存超过一定阈值时,内存中的MemTable会被冻结,切换为只读状态,转换为Immutable MemTable,同时创建一个新的MemTable,新的数据写入请求会写入到新的MemTable中,只读的MemTable会被转换为SSTable并最终写入GFS中。其目的在于减小tablet server的内存使用以及减小服务器宕机恢复时对WAL的读取。
Merging Compaction: 每次Minor Compaction都会产生新的SSTable,为了限制住SSTable的数量,后台会定期合并部分SSTable和MemTable,生成一个新的SSTable。
Major Compaction: 将所有的SSTable按照column family分别合并写入一个SSTable。定期执行Major Compaction,清除旧SSTable中的删除信息(只有在Major Compaction中旧SSTable的删除信息才会被去掉)。
Refinements
Locality Group: 用户可以将多个column family归为同一个locality group。一个单独的SSTable是按照locality group来划分的。没有较大依赖的column families可以放在不同的locality group里,省去了不必要的读操作。比如:网页表中的网页元数据(语言,校验和)与网页内容两个column family可以放在不同的locality group里,这样在读某一行的网页元数据的时候就不会将网页内容column family的数据一起读出来。
许多参数配置可以基于Locality Group去做优化。比如用户可以设置某个locality group为in-memory,这个locality group就可以被整个加载到内存当中,读的时候就可以完全不碰磁盘,METADATA表就是这样实现的。
Compression: 基于locality group配置压缩方式。基于SSTable block粒度进行压缩,这样可以使得在读取一小部分的数据时也不用解压整个文件。
Caching: 两级缓存。Scan Cache,higher-level缓存,缓存SSTable接口返回的键值对,针对频繁读的相同数据;Block Cache,lower-level缓存,SSTable对于block的缓存,针对相邻数据读取。
Commit-log: 一个tablet server下的tablets公用同一个log文件。当一个tablet server宕机需要恢复tablets时,会对log按<table; rowkey; log-sequence-number>进行并行排序来减少重复读。为了避免写日志性能骤降,每个tablet server上会有日志写入线程,分别写入各自的日志文件,但是同一时刻只有一个时活跃的,当活跃线程性能下降就会发生切换。
Bloom Filter: A Bloom filter allows us to ask whether an SSTable might contain any data for a specified row/column pair. Our use of Bloom filters also implies that most lookups for non-existent rows or columns do not need to touch disk.
Exploiting immutability:
- No synchronization of accesses to the file system while reading SSTables, resulting efficient concurrency control. That is, only memtable is mutable. Reduce contention during reads of memtable by copy-on-write on memtable row and parallel reads/writes.
- The problem of permanently removing deleted data is transformed to garbage collecting obsolete SSTables. Mark-and-sweep garbage collection.
- Split tablets quickly. Instead of generating a new set of SSTables for each child tablet, we let the child tablets share the SSTables of the parent tablet.
只列举了论文中部分refinements
Bigtable vs HBase vs Cassandra
| Hbase | Bigtable | Cassandra | |
|---|---|---|---|
| Data Model | Wide column store | Wide column store | Wide column store |
| Data schema | Schema-free | Schema-free | Schema-free |
| Typing | No | No | Yes |
| SQL | No | No | Yes, CQL |
| Distributed Architecture | Master-Slave | Master-Slave | Ring |
| Locality Group | No | Yes | No |
| CAP | CP | CP | AP |
| In-Memory Capability | No | Yes | No |
| Atomicity | Single Row | Single Row | Single Operation |
| METADATA | Two-level Index | Three-level Index | - |